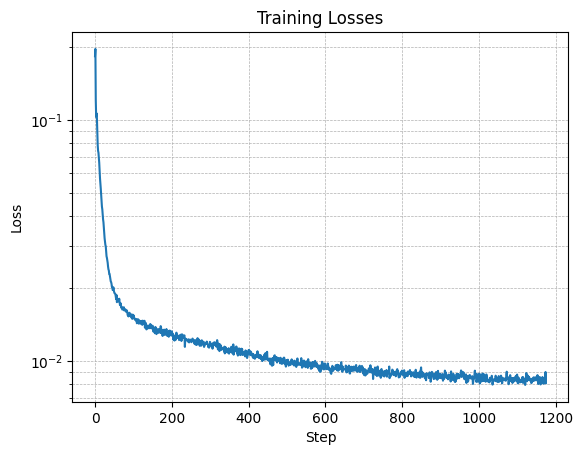
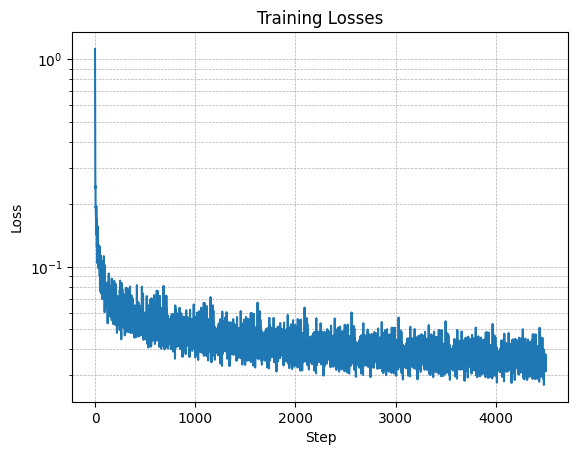
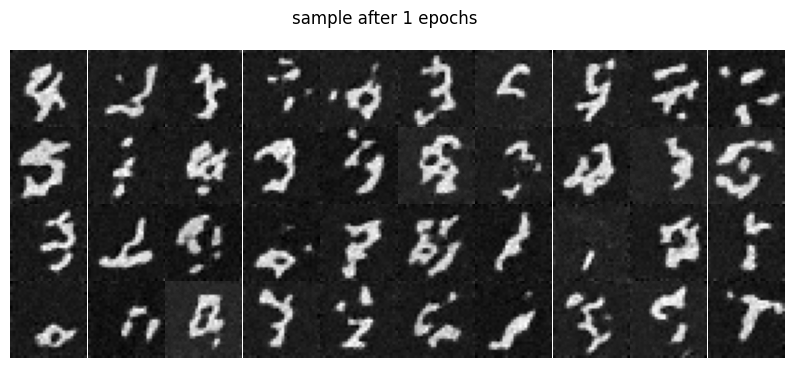
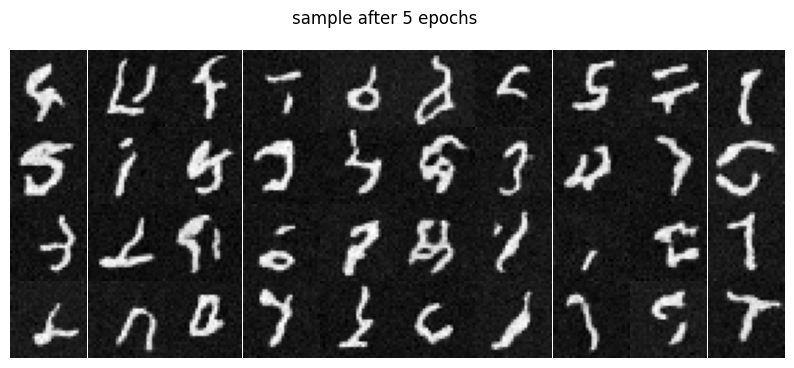
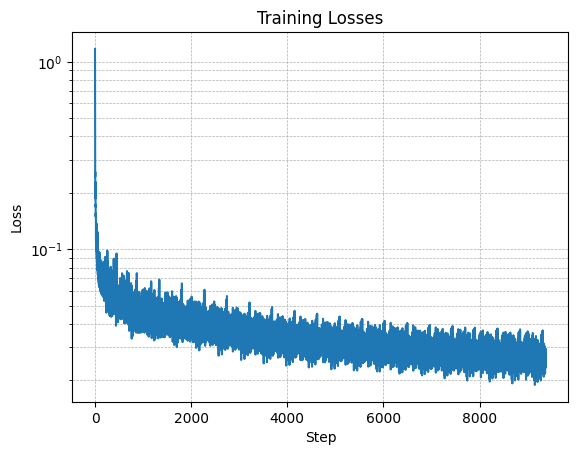
Part 0: Setup
The random seed I used is 17.
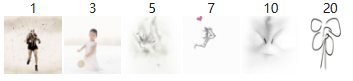
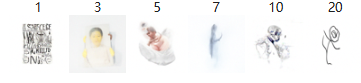
Various inference steps



The output image appear to be corresponding to the prompt. However the style between each image is different, the men wearing hat appears to be realistic while the other two images appear to be in a cartoonish style, dispite the fact that the snomy mountain village image has 'oil painting' in its prompt.
We could see that after we reduce the number of inference steps to 5, the picture start to be noisy, this is expected as there would not be enough steps for the model to do denoising.
After modifying the number of inference steps to 50, while it takes longer to output image, the quality/resolution of images seem to increase. However, the style of the snowy mountain village is still cartoonish showing this is not a problem of steps, but of prompt.